


GENCROBAT
GENCROBAT is a computational system for efficient transmission of genetic data produced by high-throughput DNA sequencing equipment to cloud computing service providers, where the data is processed and turned into information. The transmission not only helps huge sequencing data to be transferred efficiently over the Internet, but also generates highly useful information to be used in the further steps of analysis on the cloud side.
A simple analogy to describe what GENCROBAT does is, it acts as an acrobat carrying the DNA sequencing data from where it is produced to where it will be processed through a tiny rope, the communication channel. The volume it needs to transport from one point to another is so huge that it needs to travel over that rope many times. Thus, it aims to carry as much as the rope lets at each pass. To achieve this, before beginning to carry the raw data, it puts them into special vacuum bags where the goods are squeezed to carry more at each iteration. However, only the related items are packed in the vacuum bags, and thus, when a package arrives to the destination, the destination has knowledge about what is inside and where to put it. The packaging of the volumes into vacuum bags surely takes time, but since this is done in a novel proper way, the time spent on packaging is gained back on the destination during the further operations carried out there.
GENCROBAT offers an innovative solution to re-organize the processing pipeline beginning from data generation till the end of the final analysis. It assumes the life science center as a part of the big cloud, and begins with preprocessing of data on the sender side. This preprocessing not only improves the compression ratio and speed but also generates useful knowledge that will help on the cloud side.

Connecting sequencing centers to cloud
GENCROBAT platform aims to bridge the gap between sequencing centers and cloud computing services to enhance data analysis time and quality.
THE CHALLENGE
The high-throughput DNA sequencing equipments produce huge volumes of data with an ever increasing rate. While the sequencing cost decreases by ≈5x per year, the cost of computing at best decreases by ≈2x. Very soon, interpreting the omics data will cost much more than generating it.
Cloud computing services dedicated to bioinformatics seems promising to keep pace with that massive sequencing data generation. Thus, nowadays we hear a lot on cloud computing services providing speedy sequence analysis.
GENCROBAT offers an innovative solution to re-organize the processing pipeline beginning from data generation till the end of the final analysis. It assumes the life science center as a part of the big cloud, and begins with preprocessing of data on the sender side. This preprocessing not only improves the compression ratio and speed but also generates useful knowledge that will help on the cloud side.
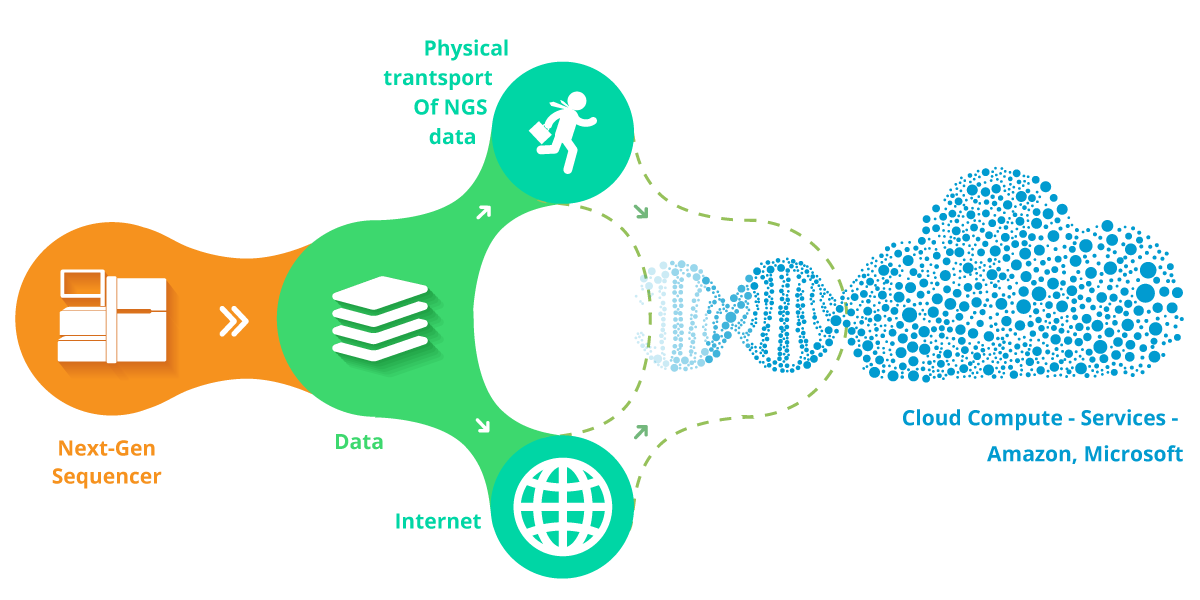
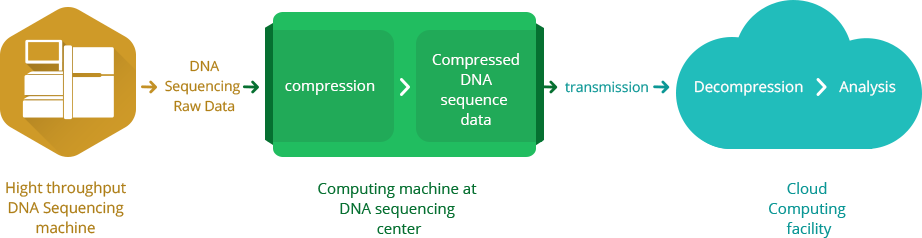
Despite the difficulties of processing sequencing data due to its volume and structure, the initial problem is to transmit the data from where it is produced to where it will be processed.
The Barriers
In such a scenario, using regular courier services will not be sustainable due to the many problems these introduce mainly stemming from the size of the data to be transmitted in practice such as privacy, tracing, accountability etc. Thus, the data needs to flow from digital lines. Notice that the size of the data to flow from the transmission lines will be so large that, even in the case of leased lines or direct connections, the importance of transmission is not expected to diminish.
Proposing an efficient solution for this problem requires a deep understanding of the needs of the life sciences, and computing capability. Since improving the way the data is compressed is not the ultimate goal, but reducing the response time is, the complete operation from transmission to the end of processing should be considered simultaneously with an industry perspective rather than with a pure computer science mindset.
The Gap
An interesting gap appears at this point. Whilst life scientists are busy perfecting their data generation, and similarly cloud service providers busy focus on speeding up their processing pipeline, the transmission of data becomes an orphan issue.
The classical method of massive data transmission is via the compress – transmit – decompress scheme. However, the compression and decompression of sequencing data is not an easy task due to its structure and massive size. Sometimes it takes more time and resources than required to analyze the genomic data itself. Moreover, the resources spent on compression does not help much in the further steps of analysis, and in some sense, the effort deployed on efficient transmission actually in the end becomes waste.
Interestingly, some DNA sequencing centers submit their data to the cloud service providers on a hard disk that is carried by a regular courier service such as FedEx, or UPS. Such a transmission is neither ideal or sustainable with the increasing number of sequencing centers.
The Opportunity
The recent advances in genomics will revolutionize medicine. Personalized medicine becoming a reality is now closer than ever. In the very near future, sequencing will become a regular diagnosis tool, and not only the research centers but almost all health institutions will begin sequencing. Not surprisingly, becoming engaged with a dedicated cloud service will be the choice of these institutions, who would not prefer the hassle of a computing infrastructure.
Institutions will surely seek for the best service which provides the shortest time response, which will be determined not by the time elapsed analysing by the cloud, but the total time elapsed between the transmission and receipt of the final result. Thus, transmitting the data in an efficient way will become of utmost importance.